背景知识
ACID
ACID 是指数据库管理系统在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:
- 原子性(atomicity)
- 一致性(consistency)
- 隔离性(isolation)
- 持久性(durability)
CAP
来自 Berkerly 的 Eric Brewer 教授提出了一个著名的 CAP 理论:一致性(Consistency),可用性(Availability)以及分区容忍性(Partition tolerance)三者不能同时满足。
- 一致性:对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据上来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致;
- 可用性:非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里的正确指的是比如应该返回 50,而不是返回 40。
- 分区容忍性:当出现网络分区后,系统能够继续工作。打个比方,这里个集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
BASE
Eric Brewer 在 1997 发表的论文 Cluster-Based Scalable Network Services 中第一次提出 BASE 的概念;eBay 的架构师 Dan Pritchett 在 2008 年发表文章 BASE: An AcidAlternative 中第一次明确提出的 BASE 理论。
BASE 是 Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写。
BASE 是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性:
- 响应时间上的损失
- 功能上的损失(降级页面)
弱状态
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
为什么要谈 ACID
BASE 和 CAP 的提出就是体系架构从单机到分布式的大背景下。
BASE: An AcidAlternative 文章的背景是讨论数据库分片对分布式事务的需求。文章使用 2PC (两阶段提交)来提供跨越多个数据库实例的 ACID 保证。但是引入 2PC 的直接影响就是可用性下降。假设数据分布在两个数据库实例上,每个数据库实例的可用性是 99.9%,那么数据库分片后可用性为:
100−((100−99.9)+(100−99.9))=99.8
作为商用软件,可用性下降是不可容忍的。因此,作者才引出了 CAP 理论,进而提出 BASE,通过放松 ACID 的严格一致性,获得系统可用性和可扩展性的提升。
我认为, 目前所有在讨论 CAP 的时候带上 ACID,一方面想说明在分布式环境下,必须在数据一致性和可用性之间做出取舍;另一方面,可能就是想单纯装一下。
CAP 理论的”三选二”
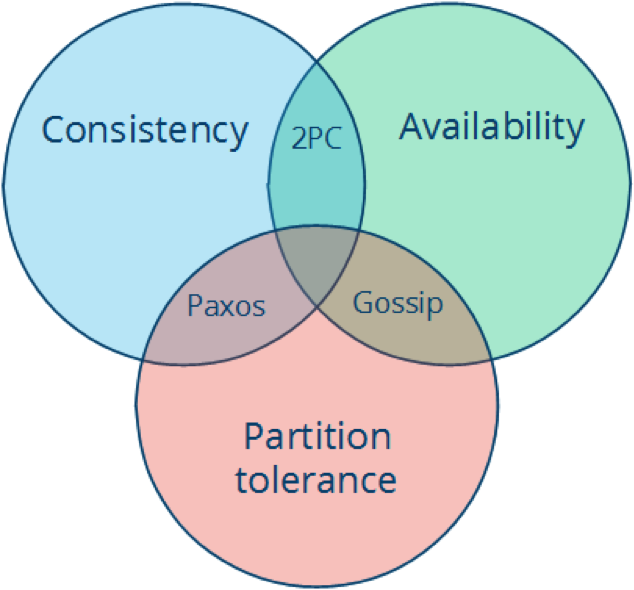
我们把 C、A、P 两两组合起来,可以得到关注点不同的系统:
- CA:这样的系统关注一致性和可用性,它需要非常严格的全体一致性协议,比如上文提到的”两段提交”(2PC)。CA 系统不能容忍网络错误或者节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道是对面的那个节点宕机还是网络错误。唯一安全的做法就是把自己变成只读的。
- CP:这样的系统关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos 算法 (Quorum 类的算法)。这样的系统只需要保证大多数节点数据一直,而少数的节点会在没有同步到最新版数据时变成不可用的状态。这样能够提供一部分的可用性。
- AP:这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本(Dynamo)。
CAP 的误解
现在很多人在进行分布式架构设计时言必谈 CAP,但是还是有很多人对 CAP 理论有误解,连 CAP 理论的作者都直言 CAP 理论的”三选二”约束一直存在着误导性。
这个约束过分简单化了各性质之间的相互关系。我们有必要辨析其中的细节。因此,我们对自己提出两个问题:
- P是必选项吗?
- CA一定要二选一吗?
P 是必选项吗
在分布式系统中,分区是由于网络问题或节点宕机导致的。这就导致程序员们就直面了一种状况:分区不会频繁出现,但是一定会出现。因此分布式系统的分区容忍性是必选项。
对于分布式系统工程实践,CAP 理论更合适的描述是:在满足分区容错的前提下,没有算法能同时满足数据一致性和服务可用性。
CA 何如取舍
但是由于分区很少发生,那么在系统不存在分区的情况下牺牲 C 或 A 我们都会觉得很心疼,怎么办呢?
CAP 定理证明中的一致性指线性一致性,即强一致性。强一致性要求多节点组成的被调要能像单节点一样运作、操作具备原子性,数据在时间、时序上都有要求。如果放宽这些要求,还有其他一致性类型:
- 序列一致性(sequential consistency):不要求时序一致,A 操作先于 B 操作,在 B 操作后如果所有调用端读操作得到 A 操作的结果,满足序列一致性;
- 最终一致性(eventual consistency):放宽对时间的要求,在被调完成操作响应后的某个时间点,被调多个节点的数据最终达成一致。
可用性在 CAP 定理里指所有读写操作必须要能终止,实际应用中从主调、被调两个不同的视角,可用性具有不同的含义。当网络分区出现时,主调可以只支持读操作,通过牺牲部分可用性达成数据一致。
工程实践中,较常见的做法是通过异步拷贝副本(asynchronous replication)、Quorum/NRW,实现在调用端看来数据强一致、被调端最终一致,在调用端看来服务可用、被调端允许部分节点不可用(或被网络分隔)的效果。
CAP 理论的这三种性质都可以在程度上衡量,并不是非黑即白的有或无。可用性显然是在 0% 到 100% 之间连续变化的,一致性分很多级别,连分区也可以细分为不同含义,如系统内的不同部分对于是否存在分区可以有不一样的认知。CAP 实践应将目标定为针对具体的应用,在合理范围内最大化数据一致性和可用性。
这样的思路延伸为如何规划分区期间的操作和分区之后的恢复,从而启架构师和程序员加深对 CAP 的认识,跳出由于 CAP 理论的表述而产生的思维局限。
无法忽略的网络延迟
CAP 理论的经典解释,是忽略网络延迟的,但在实际中延迟和分区紧密相关。CAP 从理论到实践落地的场景是如何在出现分区时对待已发生的操作:
- 降低系统的可用性取消操作;
- 冒着系统损失一致性的风险继续操作。
依靠多次尝试通信的方法来达到一致性(比如 Paxos 算法或者两阶段事务提交),仅仅是推迟了决策的时间,系统终究要做一个决定。无限期地尝试下去,本身就是选择一致性牺牲可用性的表现。
因此以实际效果而言,分区相当于对通信提出的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在 C 和 A 之间做出选择。这就从延迟的角度抓住了设计的核心问题:分区两侧是否在无通信的情况下继续其操作?
从这个实用的观察角度出发可以导出若干重要的推论:
- 分区并不是全体节点的一致见解,因为有些节点检测到了分区,有些可能没有;
- 检测到分区的节点即进入分区模式——这是优化 C 和 A 的核心环节。
- 系统设计者可以根据期望中的响应时间设置时限。但是需要注意:时限越短,系统进入分区模式越频繁,其中有些时候并不一定真的发生了分区的情况,可能只是网络变慢而已。
因此,有时候在跨区域的系统中放弃强一致性来避免保持数据一致所带来的高延迟是非常有意义的。
跳出 CAP
CAP 理论的这三种性质都可以在程度上衡量,并不是非黑即白的有或无。可用性显然是在 0% 到 100% 之间连续变化的,一致性分很多级别,连分区也可以细分为不同含义,如系统内的不同部分对于是否存在分区可以有不一样的认知。CAP 实践应将目标定为针对具体的应用,在合理范围内最大化数据一致性和可用性。
因为在分区没有出现的时候,我们完全不需要考虑分区容忍性,可以选择 CA;当分区出现之后,我们可以根据需求在 C 和 A 之间进行取舍。
因此,思路延伸为如何规划分区期间的操作和分区之后的恢复,从而启架构师和程序员加深对 CAP 的认识,跳出由于 CAP 理论的表述而产生的思维局限。例如,Oracle数据库的DataGuard复制组件包含三种模式:
- 最大保护模式(Maximum Protection):即强同步复制模式,写操作要求主库先将操作日志(数据库的 redo/undo 日志)同步到至少一个备库才可以返回客户端成功。这种模式保证即使主库出现无法恢复的故障,比如硬盘损坏,也不会丢失数据;
- 最大性能模式(Maximum Performance):即异步复制模式,写操作只需要在主库上执行成功就可以返回客户端成功,主库上的后台线程会将重做日志通过异步的方式复制到备库。这种方式保证了性能及可用性,但是可能丢失数据;
- 最大可用性模式(Maximum Availability):上述两种模式的折衷。正常情况下相当于最大保护模式,如果主备之间的网络出现故障,切换为最大性能模式。
总结
当系统中存在分区,不应该盲目地牺牲一致性或可用性。运用以上讨论的方法,通过细致地管理分区期间的不变性约束,两方面的性质都可以取得最佳的表现。
对理论的讨论就到这里为止,但是从理论到实践的落地还有很多工作要做。引入 CAP 实践毕竟不像引入 ACID 事务那么简单,实施的时候需要对过去的策略进行全面的考虑,最佳的实施方案极大地依赖于具体服务的不变性约束和操作细节。多研究现有的优秀分布式系统,分析其设计理念和对 CAP 的实现,可以更快地成长。